Developer - Repositories, repositories, repositories...
What exactly the term Repository means in the context of Dirigible? How it is related to my projects' life-cycle management? Is there a benefit to have the whole content in a single place? What is the difference between the Local and Master Repositories, and when to use them?
The Repository
In Dirigible all projects artefacts, including the configurations are stored in a single file system like structure. This content can be easily transported from one instance to another as an archive file in ZIP format, using import/export capabilities. In addition there is a secured RESTful service, which can be used for external updates of the repository content from outside remotely via HTTP.
Local Repository
The Repository running in a given instance of Dirigible is often referred as 'Local Repository' and plays the role of an operational source code storage. The analogy is the workspace directory in many desktop IDEs, such as Eclipse. When you create a project with files and folders inside, they are immediately reflected in the Local Repository. Having in mind this, the Local Repository has to be above all - fast. The default implementation used in Dirigible is File System based one. It means that Dirigible stores the projects artefacts in some root directory (default or pre-configured) on the very same instance where it runs. There is also a relational database backed implementation for a Local Repository, which can be useful in one of the deployment options described later.
Master Repository
Another kind of Repository is the so called Master Repository. This is an immutable (read-only) content provider compliant with the IRepository API. The role of this repository is to supply the initial content comprising configurations and public registry (and also workspaces if any) during the bootstrap step of Dirigble's instance. This is actually a pull transfer, where the Dirigible is the active party. This approach gives the flexibility the Master Repository itself (as a passive party) to be implemented based on file system, Git repository or any relational database.
Deployment Options
Single Persistent Instance
This is the simplest option from the operations point of view deployment option. It includes a VM with persistent state, Java Web Container (e.g. Tomcat) and Dirigible "All-In-One" product (WAR file) deployed on it. It uses a file system based Local Repository and no Master Repository is configured in this case. This option applies to trial and local development scenarios. Still interaction with Git, as well as import/export functions are available and can be used.
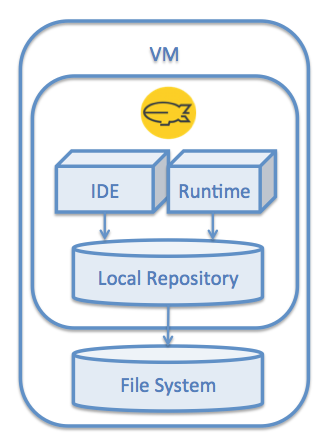
Single non-Persistence Instance
In this case we have a VM which doesn't keep its state after restart. We either have to mount a persistent file system to the image and configure a Local Repository, or we have to use a RDBMS based Local Repository connected to a remote (most likely "managed") relational database.
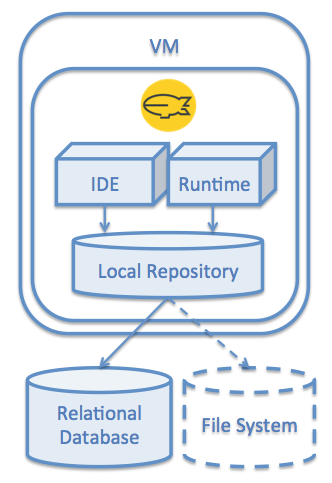
Multiple non-Persistence Instances
In this case we have multiple transient VMs connected via the RDBMS based Local Repository to a single database schema. Changes to the content (e.g. during development) can be made from any of the VM instances. After the start of a new VM image it gets the most recent content like all the others in the pool and can be used right away for development or production. The load optimisation here is based only on the in-memory cache built-in the Local Repository.
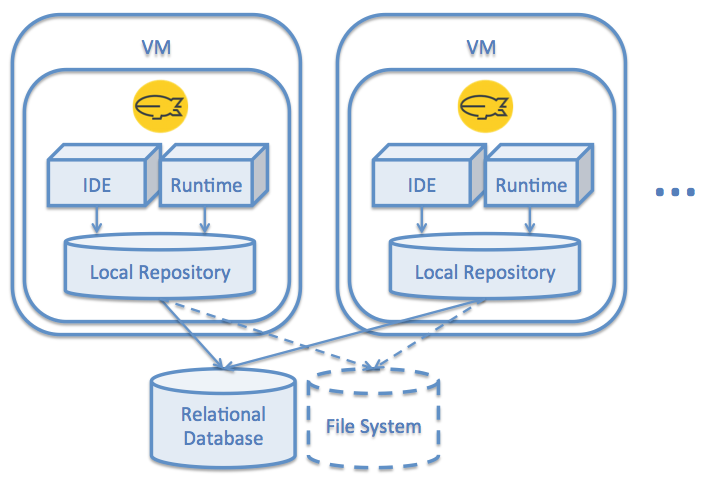
Single Master Instance and Multiple Slave Instances
If you want to have immutable production instances and a single or a few instances for development or support, you can choose this option. In this case the "development/support" instance(s) have direct connection (their Local Repository) to the "master" database schema or the "master" root directory (in case of a shared file system). All the other "production" instances have configured a Master Repository to the "master" source on one hand and a Local Repository configured as local file system based one on the other hand. This option gives the flexibility to have secure "production" instances where nobody has even theoretical possibility to break the "master" code base. At the same time to have a special instance(s) can be still accessed by different network access rules (e.g. internal access) for quick debugging and bug-fixing on the fly and on the very same environment.
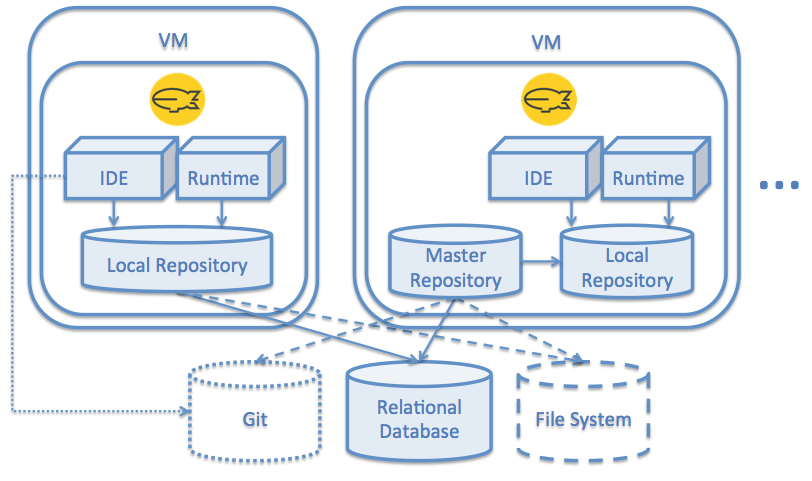
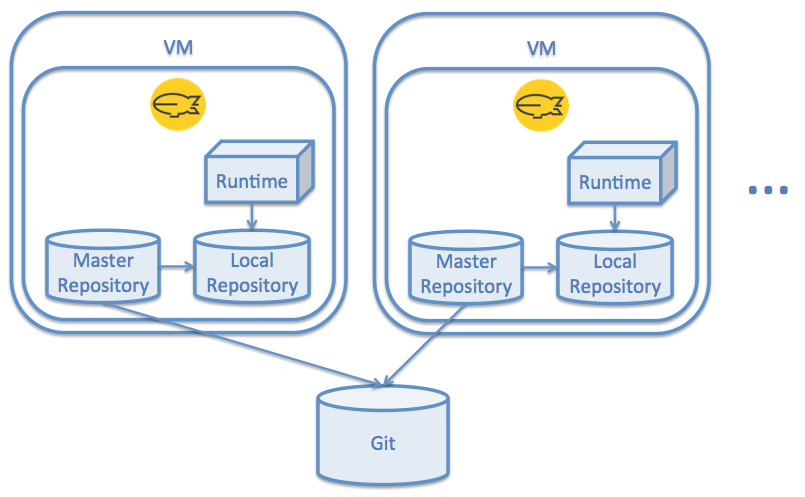
Multiple Instances with Git
Another option similar to the previous one, is that you can configure the Master Repository to retrieve the content from a Git repository. This can be useful for "production-only” instances, which have to be immutable on one hand, and versioned on the other.
Configurations
Configurations parameters for the Repository components can be provided either as initial parameters for the DirigibleBridge servlet in the web.xml or as environment variables.
For example to enable the default file-based Local Repository you can use the following snippet:
<!-- Default Repository Provider -->
<init-param>
<param-name>repositoryProvider</param-name>
<param-value>org.eclipse.dirigible.repository.local.LocalRepositoryProvider</param-value>
</init-param>
In case you want to use the database Local Repository you can use the following provider instead:
org.eclipse.dirigible.repository.db.DBRepositoryProvider
The corresponding database Master Repository can be enabled by:
<!-- Default Repository Provider Master (used for Initial Load or Reset) -->
<init-param>
<param-name>repositoryProviderMaster</param-name>
<param-value>org.eclipse.dirigible.repository.db.DBMasterRepositoryProvider</param-value>
</init-param>
and with Git-based Mater Repository:
<!-- Default Repository Provider Master (used for Initial Load or Reset) -->
<init-param>
<param-name>repositoryProviderMaster</param-name>
<param-value>org.eclipse.dirigible.repository.db.GitMasterRepositoryProvider</param-value>
</init-param>
<!-- Master Repository parameters - Git based -->
<init-param>
<param-name>masterRepositoryGitTarget</param-name>
<param-value>master_git_repository</param-value>
</init-param>
<init-param>
<param-name>masterRepositoryGitLocation</param-name>
<param-value>https://xxx</param-value>
</init-param>
<init-param>
<param-name>masterRepositoryGitUser</param-name>
<param-value>{git.user}</param-value>
</init-param>
<init-param>
<param-name>masterRepositoryGitPassword</param-name>
<param-value>{git.password}</param-value>
</init-param>
<init-param>
<param-name>masterRepositoryGitBranch</param-name>
<param-value>{git.branch}</param-value>
</init-param>
Outlook
Following the concepts of Repositories - Local and Master ones, the obvious path ahead is implementation of more production-ready connectors to different data storages e.g. NoSQL such as MongoDB or OrientDB, Cloud storage services e.g. Amazon S3, Google Cloud Storage, etc. Of course, this leaves somehow the responsibility of the security, integrity, high-availability, disaster recovery and the other important capabilities of the content Repository to the low level implementation of the data storage, but at the end this is how it should be, isn't it?